


Every year AWS outdoes itself at its annual re:Invent conference. And this year’s event was no different. The event was the largest yet, drawing more than 65,000 people to Las Vegas, and featured hundreds of new announcements from the public cloud leader. There were four keynote sessions, more than 2,500 technical sessions, a partner expo floor, as well as training and certification opportunities.
The Eplexity team attended in force. Our engineers coordinated on the different tracks to ensure we caught as many sessions as possible. This way we can deliver first-hand knowledge to our customers and partners. With so many great new products and enhancements in AWS, we wanted to share some of our favorites with you.
EC2 instance types get AWS Nitro System
AWS has added Nitro System to their underlying platform for the next generation of EC2 instances. These new Nitro instances provide faster performance and reduce costs for customers. AWS Nitro also improves security as it continuously monitors, protects, and verifies instance hardware and firmware. Nitro offloads virtualization resources to minimize the attack surface, and it’s locked down and prohibits administrative access. Dedicated Nitro cards enable high speed networking, high speed EBS, and I/O acceleration, resulting in additional cost savings for customers. EC2 instance types built on Nitro include: M5, C5, R5, T3, I3, and A1.
New AWS EBS/Snapshots features
Earlier this year, AWS announced the ability to Encryption by Default for new Elastic Block Storage (EBS) volumes in a region. Covered at re:Invent, this new offering ensures all new EBS volumes created in your account are encrypted. Encryption by Default opt-in settings are specific to individual AWS regions in your account. This encryption default key is set to the default aws/ebs KMS key for your Region but can be set to a customer managed key (CMK) if needed.
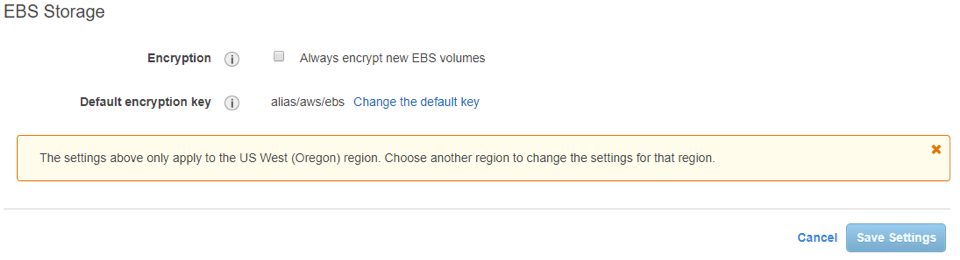 AWS also launched Fast Snapshot Restore (FSR) for EBS. FSR can be enabled for new and existing snapshots on a per Availability Zone (AZ) basis, then new EBS volumes can be created without initialization. FSR also allows for faster boot times, which speeds up VDI environments and gets autoscaling groups up and running more quickly. FSR can be enabled on a snapshot even while the snapshot is being created. If nightly backup snapshots are created, enabling them for FSR will allow you to do fast restores the following day regardless of the size of the volume or the snapshot.
AWS also launched Fast Snapshot Restore (FSR) for EBS. FSR can be enabled for new and existing snapshots on a per Availability Zone (AZ) basis, then new EBS volumes can be created without initialization. FSR also allows for faster boot times, which speeds up VDI environments and gets autoscaling groups up and running more quickly. FSR can be enabled on a snapshot even while the snapshot is being created. If nightly backup snapshots are created, enabling them for FSR will allow you to do fast restores the following day regardless of the size of the volume or the snapshot.
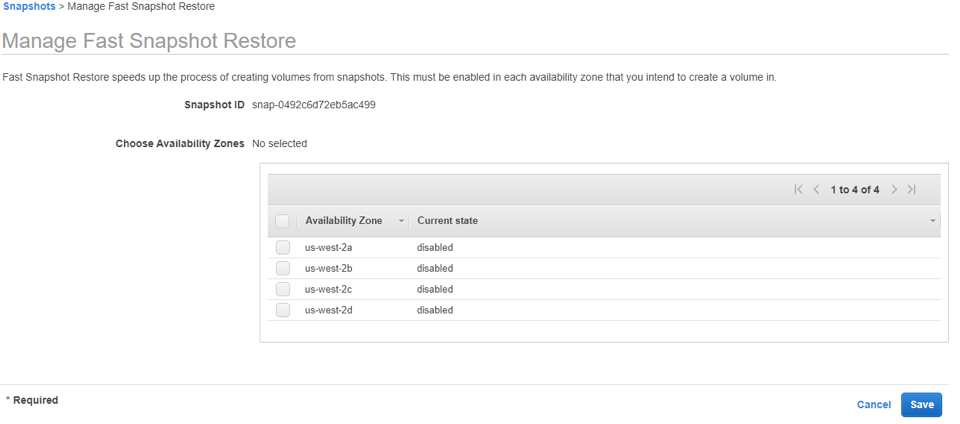 CodeGuru
CodeGuru
AWS announced CodeGuru, which uses machine learning to run automated code reviews. When CodeGuru is being used, a developer can commit their code and CodeGuru will provide a readable assessment of that code which includes provides recommendations for application best practices, cost-optimization, and performance improvements. CodeGuru reduces the workload on developers that are currently performing their own manual code reviews. Currently, CodeGuru only supports Java, but other languages are expected to be added in the future. You can associate existing code repositories on GitHub or AWS CodeCommit with CodeGuru.
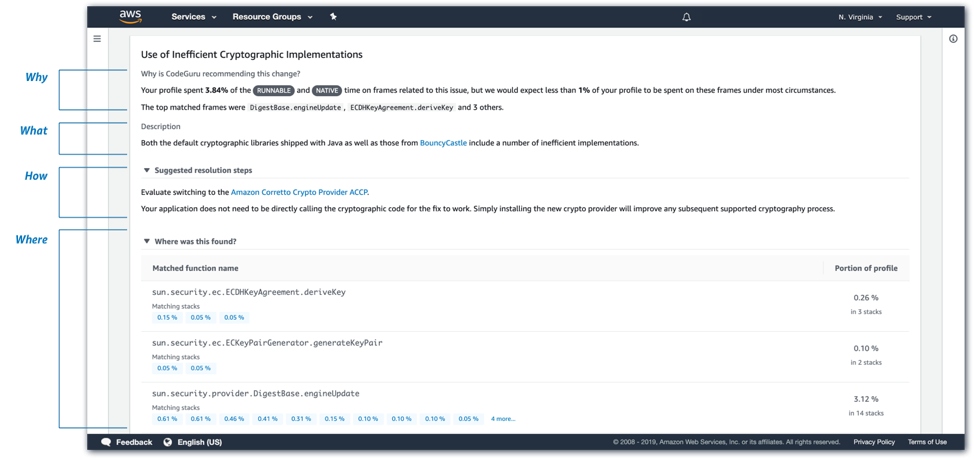 Amazon EKS on AWS Fargate
Amazon EKS on AWS Fargate
AWS Fargate allows customers to focus on developing their application without managing the underlying infrastructure, by taking care of provisioning, patching, and scaling of servers automatically. Previously, AWS Fargate was available only for applications running on Amazon Elastic Container Service (ECS). Now, it is possible to run Kubernetes pods on Fargate with Amazon Elastic Kubernetes Service (EKS). Customers no longer need to provision or manage their own EC2 instances for EKS. When using Fargate, customers only pay for the vCPU and memory consumed by their application, as opposed to the EC2 and EBS charges that are accrued when using EKS without Fargate. This makes it easy to right-size resource utilization for each application and allow customers to clearly see the cost.
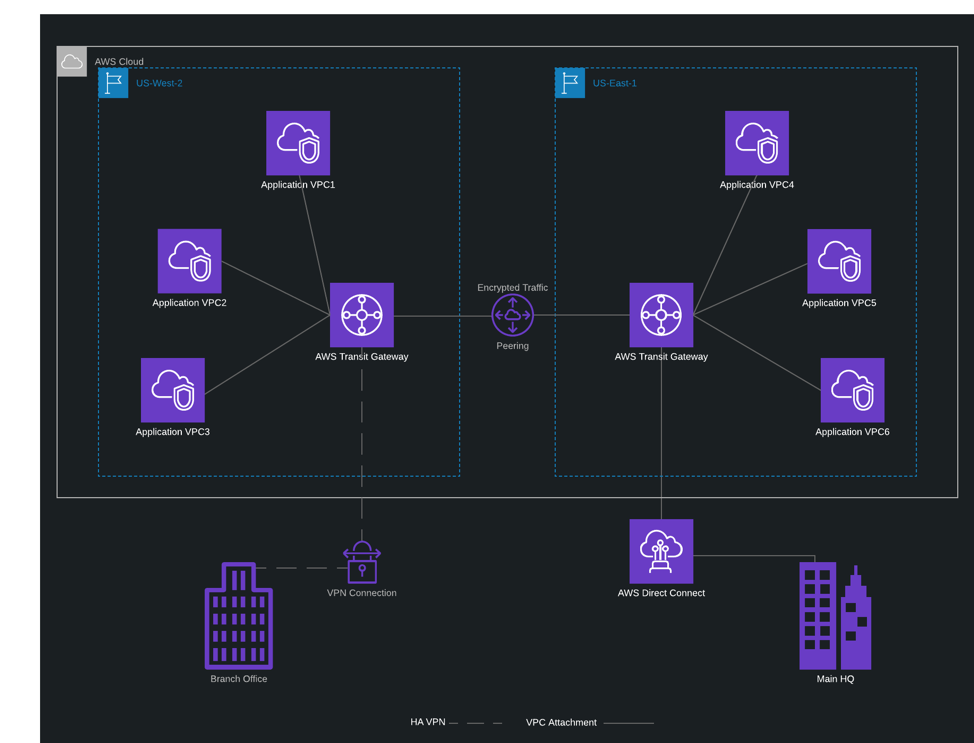
 Transit Gateway Inter-Region Peering
Transit Gateway Inter-Region Peering
Last year, the introduction of Transit Gateway AWS made huge strides into simplifying native and hybrid network configurations. This year the trend continued with AWS introducing inter-region peering for Transit Gateway. Transit Gateway peering is available today in all US regions except for California. With inter-region peering for Transit Gateway you can now extend connections between the hub and spoke designs within a region to include connectivity to most other AWS regions. In addition to just providing connectivity and to ensure the security of data after it leaves an AWS region, AWS anonymizes all network traffic as it enters the peering connection and takes the extra step of encrypting all traffic as it moves between regions.
One of the recurring themes at this year’s re:Invent was data. There were significant announcements in Redshift, Athena, and SageMaker. The most significant announcements for Redshift came in the way of two features – one was the introduction of new instance type and the other was the introduction of Federated Queries. When configuring the cluster size for large loads in Redshift, the choices of the node type has to be based on the worse case of either CPU or required storage to store. Often, the instance type chosen results in the over provisioned on one of the two.
Redshift RA3 instance type
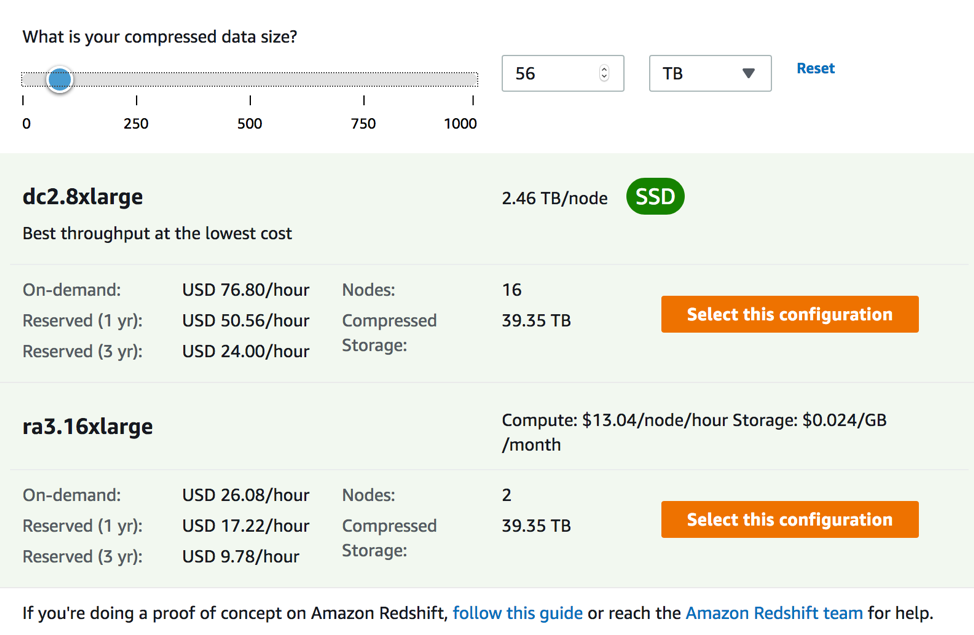
AWS announced the RA3 instance type which separates storage from compute for Redshift clusters. Normally the instances for Redshift binds the CPU and Storage. For small Redshift clusters it might not be a huge problem. For RA3, the Storage is designed to be separate from the CPU. In addition, the storage is priced separately from the compute. The storage is also provisioned dynamically based on requirements.
 Large datasets such as a 60TB compressed data source might require dc2.8xlarge. As shown below, the Redshift cluster (16 nodes) would cost $76.80 hour on demand but with the RA3 instance type, the cost dramatically drops to $26.08 per hour, a 67% reduction in cost. This new instance type makes cost more manageable for large data sets running in Redshift.
Large datasets such as a 60TB compressed data source might require dc2.8xlarge. As shown below, the Redshift cluster (16 nodes) would cost $76.80 hour on demand but with the RA3 instance type, the cost dramatically drops to $26.08 per hour, a 67% reduction in cost. This new instance type makes cost more manageable for large data sets running in Redshift.
 Athena Federated Query
Athena Federated Query
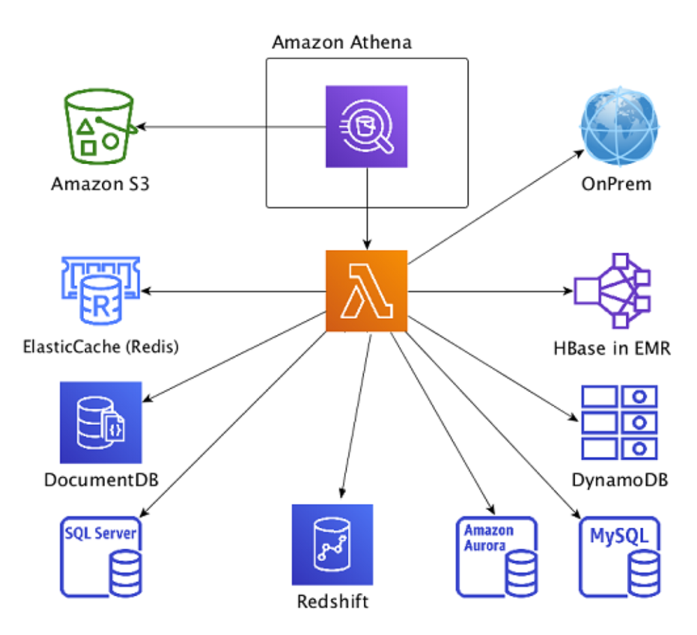
The challenge of learning multiple programming languages, creating several pipelines, and then normalizing the data for querying has been addressed with Athena Federated Queries. Users can utilize Athena Data Source Connectors to run SQL queries on AWS Lambda. AWS has open source data source connectors for Amazon DynamoDB, Apache HBase, Amazon Document DB, Amazon Redshift, AWS CloudWatch, AWS CloudWatch Metrics, and JDBC-compliant relational databases such as MySQL, and PostgreSQL. Additionally, using the Athena Query Federation SDK, a user can build connectors to any data source. This is a game changer for any size company who needs to leverage multiple data sources for rapid data analysis and decision-making.
The Diagram below shows how using Athena you can invoke Lambda-based connectors to connect with data sources that are on on-premises and in Cloud in the same query. In this diagram, Athena is scanning data from S3 and executing the Lambda-based connectors to read data from multiple data types and sources.
SageMaker Big Data Sampling
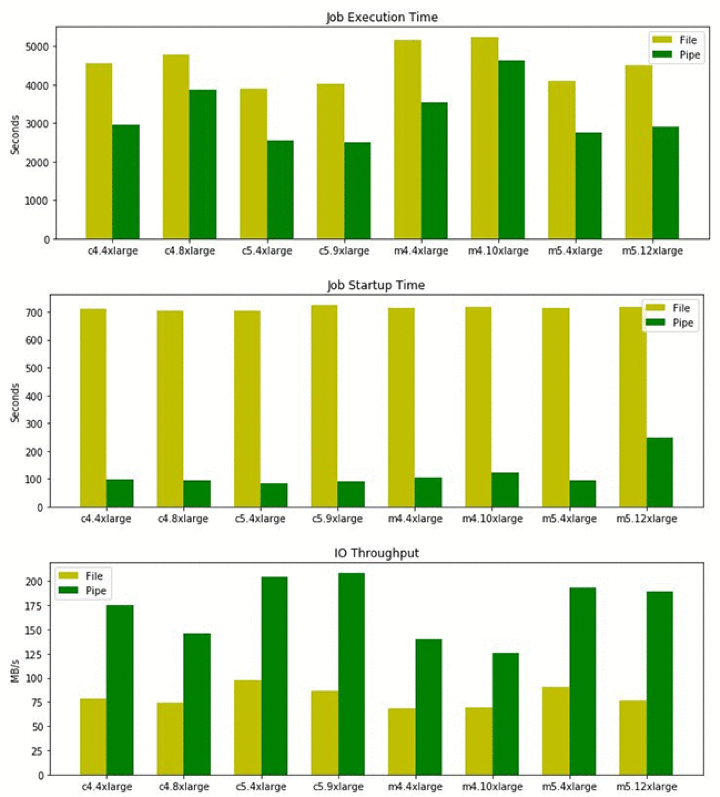
Although announced in May of last year, one of the best sessions on SageMaker was the use of SageMaker Pipe mode. As training data sets grow, ingesting the data into the SageMaker instances, becomes more of an issue. Typical SageMaker training algorithms leverage files on S3 to bring in the S3 into the algorithm. That training data will reside on EBS storage. The training models cannot start until all the data is loaded from S3 into the EBS volumes.
Now, with the use of Pipe mode, the data is streamed into the instance running SageMaker. When streaming the data, the size of that data set does not determine the startup time of the algorithm. In addition, the size of the data is no longer restricted to 16TB (EBS Max size). Pipe mode brings in the data in, one sample at a time, without using any local storage. Amazon did some benchmarks based on an 80GB data set. The graphs below, show a significant change in startup time and overall reduction in execution time.
When managing large data sets in SageMaker, there is now a proven method to manage, ingest, and use tens and hundreds of terabytes. With PIPE mode, other considerations need to be addressed, based on the algorithms used.
- How to best to sample the data when streaming and not using stored data frames
- How to create boosted data samples in order the sampling weight of some data high than others
- How to convert the data format to be supported by SageMaker and PIPE mode
SageMaker Ground Truth
Although not a new service this year AWS continues to improve the experience of AWS Ground Truth and simplifies the ML workflow process. This year the Ground Truth team introduced some great new training examples for how to use many kinds of workers for data labeling training sets while ensuring high quality. You can find many of the great new examples here at the teams Github.
 AWS Identity and Access Management (IAM) Access Analyzer
AWS Identity and Access Management (IAM) Access Analyzer
AWS IAM Access Analyzer is a new feature that allows teams to verify the policies set are only providing the intended access to the specific resources, such as compute instances and storage buckets. Access Analyzer is easy to enable with just one click on the IAM console. Once enabled IAM Access Analyzer continuously analyzes and monitors for new and updated policies, allowing proactive actions and automating security measures that violate security compliance or best practices. Access Analyzer delivers detailed findings that can be exported and used for reporting for auditing purposes, providing visibility into who has access to the different AWS resources.
IAM Access Analyzer uses analysis and mathematical logic to determine the access paths allow by a resource policy. Using this form of mathematical analysis IAM Access Analyzer can deliver the findings from across the account in seconds even if there are thousands of policies in the environment. IAM Access Analyzer also provides the ability to test and prove the resource policy is providing the correct access path to resources, giving a provable security model.
There is no additional cost in all commercial AWS Regions in the AWS Console and through APIs. IAM Access Analyzer is available via APIs in AWS GovCloud (US). Of note, Access Analyzer is per region and will need to be enabled for each region that contains AWS resources.
 We’ve only hit upon the tip of the iceberg. If you’d like more information on any of the solutions listed here, or on AWS generally, let us know. We’re focused on your success by simplifying the AWS eco-system into a manageable process for you and your team.
We’ve only hit upon the tip of the iceberg. If you’d like more information on any of the solutions listed here, or on AWS generally, let us know. We’re focused on your success by simplifying the AWS eco-system into a manageable process for you and your team.

